
Let a 1,000 flowers bloom. Then rip 999 of them out by the roots.
For the past eleven months I’ve been the tech lead for Twitter’s Engineering Effectiveness group. Engineering Effectiveness is our name for what elsewhere might be called Developer Tools, Developer Productivity, Engineering Infrastructure, or Developer Efficiency. We provide the tools and processes that allow the rest of Twitter engineers to do their job, focusing on the things that are used by most Twitter engineers and which are not super Twitter specific: build tools, continuous integration systems, source control, and so on.
I recently gave a talk at Facebook’s @Scale conference about how teams like Engineering Effectiveness scale our work. This essay is the extended dance remix of that talk. The tl;dr is the same however: as an industry we mostly don’t know how to do it and consequently massively under-invest in making our engineering orgs actually effective.
Every software company starts with a single line of code written by the first developer and grows from there. Twitter did. Facebook did. Your company did. But what happens after that?
As an industry we, for the most part, know how to scale up our software. We know how to build abstractions and modularize our code so that we can manage large code bases and how to deploy our software so it can handle the demands of millions or even billions of users. We also know how to scale up our organizations, putting in the necessary management structures to allow thousands of people to work together more or less efficiently.
On the other hand, I’d argue that we don’t really yet have a good handle on how to scale that area that exists at the intersection of engineering and human organization—the place where groups like Engineering Effectiveness work. And, worse, it often seems that we don’t even understand the importance of scaling it as we go from that first line of code to thousands of engineers working on millions of lines of code. At any rate, that’s what a bit of Twitter history would suggest.
Scaling our software: let a thousand flowers bloom
Twitter’s first line was written in 2006 by our now interim CEO, Jack Dorsey. He later claimed in a tweet that he originally wanted to write it in Python, C, and OCaml but because he soon hired a Rails core contributor they went with Ruby on Rails. What started as a simple Rails app grew into what was eventually probably the largest monolithic Rails app on the planet, known as the Monorail.
However Twitter wasn’t all Ruby for long. In 2008, Twitter acquired a five-person search company whose technology stack was Java based. At the time there were about nine Twitter engineers and a handful of ops people, so adding five new engineers who came in with their own code base and way of working immediately increased the diversity of engineering styles and practices within Twitter. Let a thousand flowers bloom.
2008 was also the year the first Scala was written at Twitter. So now we had the main product, twitter.com, as a Rails app, search using Java, and folks experimenting with Scala. Let a thousand flowers bloom.
In 2009 someone started a repo called Science. At the time creating a new repo for a new project was just what one did so no big deal. However, that repo grew to become the main repository for Java code which included the search code, most of the ads team’s code, and associated data science code that need to operate on data structures defined by the ads code. While the platform group was moving more and more toward Scala, partly because Scala could be made to look more like Ruby than Java could, the ads team was going the other direction. Alex Roetter, now our SVP of Engineering, then an engineer, personally led the effort to convert what Scala code the ads team had already written into Java. Also around that time, a couple of other engineers started trying to make Science into a Google-style monorepo with our own homegrown build system, Pants. Let a thousand flowers bloom.
Finally, we arrive at 2010, year of the quadrennial soccer World Cup. Excitement about the Cup was high on Twitter. A bit too high, in fact. More or less every time someone scored a goal, the Tweets per second would spike and knock over the site. GOOOOAAAAALLLL! Fail Whale. GOOOOAAAAALLLL! Fail Whale.
Consequently, in the aftermath of the World Cup, we decided that we really needed to move off the monorail and onto a JVM based service oriented architecture. Around the same time, Marius Eriksen, now a Principal Engineer, and some others were working on a new Scala RPC library, Finagle, which soon became the standard around which new services were written. The “off the monorail” effort began in earnest and we started teaching Ruby developers Scala so they could write services to replace the Monorail. And over on the ads side some data scientists started work on a Scala DSL for writing Map Reduce jobs that became Scalding. Soon we had three kinds of Scala written at Twitter: Scala written by people who wished it was Ruby, Scala written by people who wished it was Java, and Scala written by people who wished it was Haskell. Let a thousand flowers bloom.
Yet despite this diversity and perhaps because of it, we made real progress on the reliability and scaling of our software. Fast forward four years to the next World Cup and it’s a totally different story. We handled a massive tweet volume basically without problem—35.6 million tweets during Germany’s 7-1 shellacking of Brazil in the semi-final with a peak of 580,166 Tweets per minute shortly after Germany’s fifth goal. A lot of things, obviously, happened in those four years that I’ve not discussed including a lot of very specific work in the run-up to the 2014 World Cup. But the point is we did figure out how to scale our software.
The garden is overrun
Around the same time as we were celebrating our success at handling the World Cup traffic, things were coming to a head on the internal tools front. The Science repo had grown up to be one of Twitter’s two monorepi. The other monorepo was formed from all those Scala services that had spun out of the off-the-monorail effort. They had started out as separate repos but were eventually consolidated into a single repo, Birdcage, in order to make it easier for Finagle developers to upgrade their library and all its clients together.
Why, you might ask, when the Scala developers decided they needed a monorepo didn’t they move their code into Science; why make another monorepo? Good question. Some of it had to do with tooling issues: The build system in Science was Pants—written by an ex-Google engineer and inspired by Google’s Blaze build system. At the time the Birdcage was made, Pants didn’t know how to build Scala and the Pants view, inherited from Google, about how a repository should be organized was at odds with how Scala repos built with sbt—the Scala Build Tool—were organized. There were also perhaps some nerd posturing between the fans of Java and fans of Scala. But the real issues was this was nobody’s job: there was a team called Developer Productivity that was somewhat involved but it did not have the charter or the people to say, “Hey, we should really do the work necessary to get all this Scala code into Science and not make another monorepo,” nor to force the Java and Scala partisans to find some way to get along.
Unfortunately Finagle had also really taken off and eventually code in Science had started taking dependencies on Finagle. And code in the Birdcage took dependencies on libraries in Science. Updates on one side had to be published and consumed by the other side, a time consuming process for just one hop and some projects had multiple back and forth hops. So we had two monorepi and a situation that could be visualized as suggested by the eponymous @monorepi Twitter account:
software engineering pic.twitter.com/Iz8kDUEnOw
— monorepi (@monorepi) November 20, 2013
Somewhere along the way someone decided that it would be easier to convert the Birdcage to use Pants which had since learned how to build Scala and to deal with a maven-style layout. However at some point prior Pants had been open sourced in throw it over the wall fashion and picked up by a few engineers at other companies, such as Square and Foursquare, and moved forward. In the meantime, again because there weren’t enough people whose job it was to take care of these things, Science was still on the original internally developed version and had in fact evolved independently of the open source version. However, by the time we wanted to move Birdcage onto Pants, the open source version had moved ahead so that’s the one the Birdcage folks chose.
To make matters worse—again because of insufficient investment—neither version of Pants worked entirely reliably. Consequently different teams had evolved their cargo-culted strategies for making it work well enough to get by. For some teams this included running a script, wash-pants, that aggressively wiped out all of the state Pants cached between runs to speed up builds.
And we had also started using Thrift as our data interchange format but couldn’t agree on which Thrift compiler to use or whether we should published Thrift IDL jars or already compiled artifacts. Again, there were definitely people with opinions about all these questions—we were a bunch of engineers, after all—but nobody who was in a position to make them and to have the time to do the work to make them stick. Let a thousand flowers bloom, indeed.
All of which is to say, it was a mess. When I arrived at Twitter in April 2013 to work on A/B experimentation systems, the full conversion of Birdcage to pants was “imminent”. It was, in fact, not completed until more than a year and a half later. And in late 2013 the then SVP of Engineering, Chris Fry, declared that we would move our code into a monorepo, which basically meant merging Science and Birdcage. In May of 2014 he said we’d definitely be in the monorepo by July 11th of 2014. He was gone from Twitter a couple weeks after the announcement but the new head of engineering, Alex Roetter, last seen excising Scala code from the ads code base, reaffirmed the goal. But the date came and went with no monorepo.
A few months after he became head of engineering, Roetter decided enough was enough and hired a new VP, my boss Nandini Ramani, to head up a new organization Engineering Effectiveness, which would subsume the old Developer Productivity group and a few other teams in order to expand the scope of work we could do to support the rest of Twitter engineering. She recruited me into EE a couple months in. Since then, the reinvigorated and renamed Engineering Effectiveness team has been finishing off projects like the monorepo consolidation but also thinking about what it takes to actually provide world-class tools and support to Twitter engineers.
So what happened? Why could Twitter scale our software so well yet have so much trouble with the software we built for ourselves to help us do our jobs?
How to think about engineering effectiveness
I think a big part of the problem is that we—as an industry—are not very good about thinking about how to make engineers effective. For our software, especially back-end software, we can measure its goodness by the number queries per second it can handle, the number of incidents we experience, and the amount of hardware we have to buy to run it. Those things are easy to measure and even fairly easy to tie to financial implications for the business.
Engineers’ effectiveness, on the other hand, is hard to measure. We don’t even really know what makes people productive; thus we talk about 10x engineers as though that’s a thing when even the studies that lead to the notion of a 10x engineer pointed more strongly to the notion of a 10x office.
But we’d all agree, I think, that it is possible to affect engineers’ productivity. At the very least it is possible to harm it.
The Twitter EE motto is: “Quality, Speed, Joy”. Those are the three things we are trying to affect across all of Twitter engineering. Unlike that other famous triple, Fast, Cheap, Good, we believe you don’t have to pick just two. In fact they feed into each other: Building things right will let you go faster. Building faster will give you more time to experiment and find your way to the right thing. And everybody enjoys building good stuff and a lot of it.
But how can Engineering Effectiveness actually affect quality, speed, and joy?
One place to start is with simple time savings. If we assume there’s a certain amount of time engineers spend every day waiting for things to happen—time that isn’t being put to productive use—we can give people an effectiveness boost just by eliminating some of that down time. Assuming a standard standard 8-hour—or 480-minute—day we only have to save everyone about five minutes a day to get a 1% speed gain. Obviously to save everyone five minutes a day, every day, we have to be working on something that everyone uses all the time. How easy that is depends, obviously, on how much down time is currently induced by your tools and processes. It’s also possible to save time by removing things that will periodically eat larger amounts of time. An extra hour spent every couple weeks debugging a problem due to confusing error messages or logs is equivalent to five minutes a day and thus 1% of your total time in the year.
Another more dramatic way we can influence people’s effectiveness is to help them stay in flow state. I assume you’ve heard of the psychological state of flow, a.k.a. “being in the zone”, when everything is just clicking, and you can concentrate, solve hard problems, etc. It’s generally thought that it takes about fifteen minutes to get into flow and only an instant to lose it, if you are interrupted.
Modern open plan offices are inimical to flow but that’s an essay for another day. Our present concern is whether the tools we provide to our engineers are helping to keep them in flow or are they, in fact, the thing breaking them out of flow. Even using the simple analysis of time savings we just went through, one way to save people fifteen minutes a day is to break their flow one less time per day. But flow conducive tools probably provide way more of a boost than just saving fifteen minutes since flow is such a powerful state and losing flow so costly. Flow is also, obviously, the name of the game when it comes to increasing developer joy.
But as bad as flow-breaking interruptions are, there’s something much worse out there sapping our engineers’ effectiveness. We know from Dune that fear is the mind killer. So how does fear manifest in the context of software development? I would say tech debt. Tech debt is the mind killer.
Tech debt is the lack of quality. It slows us down. It makes us miserable. It breaks our flow and saps our will to live. As with financial debt, a small amount, taken on with eyes wide open, can be a good thing. But also like financial debt, it compounds over time. A little bit of technical debt taken on when you were ten or a hundred engineers, left on the books, will be killing you when you’re a thousand engineers.
Engineering Effectiveness teams often have an intimate relationship with tech debt because it so often piles up in tooling: until you have people whose job it is to work on them, tools tend to be something hacked together just well enough to get something done. The good news about that, is after you’ve cleared the accumulated tech debt out of your tools, your team will be well positioned to help other teams tackle their own tech debt, which will lead to really massive gains in effectiveness.
We haven't gotten there quite yet but one of my dreams for EE at Twitter is to establish a standing cruft slaying army. These would have to be experienced, senior folks with the chops to dive into a section of the code base and make both the code and the people working on it better.
Another area where an engineering effectiveness team can help is to coordinate with engineers to push the good ways of doing things and stamp out the bad ways, whether it’s how we do code reviews, test our code, write design docs, or anything else. However, if you expect your EE team to get involved in these questions, you’d better make sure you have strong senior engineers as part of that team because they’ll be making decisions and recommendations that will affect a lot of other engineers.
Finally there’s a psychological aspect to providing good tools to engineers that I have to believe has a really impact on people’s overall effectiveness. On one hand, good tools are just a pleasure to work with. On that basis alone, we should provide good tools for the same reason so many companies provide awesome food to their employees: it just makes coming to work every day that much more of a pleasure. But good tools play another important role: because the tools we use are themselves software, and we all spend all day writing software, having to do so with bad tools has this corrosive psychological effect of suggesting that maybe we don’t actually know how to write good software. Intellectually we may know that there are different groups working on internal tools than the main features of the product but if the tools you use get in your way or are obviously poorly engineered, it’s hard not to doubt your company’s overall competence.
Let’s build a model
So let’s take as a given that there are things we can do that will increase the quality of the software our engineering org produces, the speed with which it produces it, and the joy our engineers experience in their work and that increasing any of those, in a real way, will ultimately benefit the company. For lack of a better term, let’s just call that “effectiveness”.
So here’s a simple model for the total effectiveness of an engineering org:
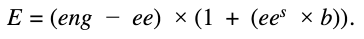
E is the total effectiveness of an org where eng is the total number of engineers, ee is the number of engineers devoted to an Engineering Effectiveness style team, b is the boost the first EE engineer gives to the remaining engineers’ effectiveness, and s represents how each additional EE engineer scales the total productivity boost. If s was one then each EE engineer would add a boost of b. If it’s less than one, as seems likely, then each new EE engineer has a smaller effect than the previous one.
Now, this is obviously a very simple model and like all models, is wrong. But it may be useful. Assuming your total number of engineers is more or less given, the two interesting parameters to this model are the scaling factor, s, and the boost, b. Frankly, I don’t have any great ideas about how to set s. I’m pretty sure it’s less than one. If it was 0.5 that would mean that the total boost would grow as the square root of the number of EE engineers; i.e. to double the total boost you would have to square the number of EE engineers. That seems a bit too steep a fall off. So let’s say 0.7 is a reasonable guess. For b we can think about all the ways just discussed that EE folks can help boost the effectiveness of other engineers. Between simple time savings, helping keep engineers in flow, removing tech debt, encouraging and supporting good practices, and increasing joy by providing excellent tools, it seems like an across the board 2% effectiveness boost is reasonable, perhaps even conservative.
So now let’s look at some graphs of total effectiveness depending how many of our engineers we devote to effectiveness work assuming s = 0.7 and b = 0.02. As I say, these seem to me fairly conservative values. Later on you can play with this model and put in your own values.
In the first plot we see that for an engineering org of ten people it’s in fact not worth it to devote any engineers to tooling as the maximum effectiveness—pointed out by the arrow—is the ten engineers worth you get when you devote zero engineers to engineering effectiveness. In such a small engineering org, individual engineers will probably automate things that are bugging them, making the simple trade-off of how quickly the time they spend on automation will be paid off by time saved by the automation but it’s not worth dedicating anyone to it.
If you look closely at the chart, however, you can see that while it looks like a straight line, it’s actually slightly curved: when you devote one engineer to EE work, you lose their work but you gain back a bit because that engineer is making the other nine more effective. The problem is with only nine other engineers, the benefit doesn’t add up to enough to make up for the lost work of the EE engineer.
At one hundred engineers, with these parameters, the curve starts to bend more noticeably as we have enough engineers for the effectiveness gains to make up for the cost of a couple EE engineers. The model suggests we should devote two engineers to EE who will bring the total productivity up to 101 engineers worth, so a free engineer’s worth of work.
However once we get to a thousand engineers, the small gains per engineer start to add up, even though each additional EE engineer is adding less and less of an effectiveness boost. If these parameters are right, for a thousand person engineering org we should devote over a quarter of our engineers—255—to engineering effectiveness, yielding a total effectiveness equivalent to 1,465 engineers for the price of 1,000.
And if we assume the model still works as our engineering org grows another order of magnitude, to 10,000 engineers, then we’d want to have more than a third of our engineers doing EE style work, 3,773 out of 10,000 giving is a total effectiveness equivalent to 45,945 engineers with no EE.
I have to admit that I have a hard time imagining an EE org bigger than all of Twitter but I also have trouble imagining a 10,000 person engineering team. But note that even in the step from 100 to 1,000 engineers the optimal number of EE engineers grew much faster than the total number of engineers and the payoff was disproportionately large. This is why it’s so important not to under-invest in supporting our engineers.
Weeding the garden
There is one caveat to all this, however. In order for engineering effectiveness engineers to be able to boost effectiveness across all of engineering, things need to be standardized. As we just saw, the big investments in engineering effectiveness work only starts to pay off when you are doing the work for lots of engineers. You may work for a 1,000 person engineering org but if the tool or process you’re working on is only used by a hundred of them, one hundred is the relevant number not 1,000.
This is where tearing out those 999 flowers by the roots comes in. Once your engineering org gets to be a certain size the benefits you can obtain by investing in making all your engineers slightly more productive start to swamp the slight gains that one team might get from doing things their own, slightly different way. During the “let a thousand flowers bloom” phase people will have planted all kinds of exotic blossoms, some of which are lovely and even well adapted to their local micro-climate; you need to be able to decide which ones are going to be first class, nurtured members of your garden and which ones are weeds.
I get that this is a delicate balance to get right. Everyone would love for you to make some decisions about how to do things and bring some consistency, as long as you choose their current preferred way of doing things. On the other hand, when things are sufficiently chaotic, lots of people will be happy to have someone come in and make some decisions about how to do things and actually make those decisions work.
So you’ll need engineers with good technical judgment and the technical chops to get ahead of the chaos and dig out from under accumulated tech debt that has probably piled up in your tools. But the good news is, each time you deliver some real improvement in quality, speed, and joy for your company’s engineers, you’ll earn a little more trust to make decisions.
Your goal should be to pick the set of tools and processes you will support and support the heck out of them. Invest more than you probably think you need to and focus relentlessly on making the tools and processes you do support awesome. Get senior engineers involved from early on so they can make good choices for your engineering org and get buy in to make them a reality. If you get behind, as Twitter did, you may need to invest even more to get your garden back in shape. When you’re behind and the “official” ways don’t really work well, you’ll get more flowers blooming because people and teams will need to find their own ways to get their work done.
But once you get to the point where all the flowers you tend are awesome, people will use them. And if they don’t it will be because they have a real reason not to. And when you’re not overwhelmed trying get your existing stuff working, you should have the time to treat a team going their own way as a chance to learn something about how the product you’re offering doesn’t quite meet your customers’ needs.
In other words, when your garden is tidy and well tended, if a pretty new volunteer sprouts up you don’t have to freak out because you’re afraid it’s going to overrun the garden. You can watch it grow and if it looks like it might be a valuable contribution to the garden, you can start to nurture it like the rest of your flowers.
We’re in the middle of this at Twitter. Engineering Effectiveness, the team, is only a year old and we’re still operating somewhat in weed whacker mode and have lots of opportunities to dramatically improve the effectiveness of Twitter engineers simply by making our existing tools better. Maybe in a year or so I’ll have a more sophisticated model and a theory about how, once you get everything sorted, you can scale back your EE style teams because it doesn’t take nearly as many people to tend a well-maintained garden than to whip one into shape. But I don’t think the path that Twitter took, as it grew from one to tens to hundreds to thousands of developers is all that different from the path other companies have taken or will take in the future so perhaps you all can learn from us some of the consequences of not investing enough, soon enough, in supporting your engineers.
In the meantime, I wish you all Quality, Speed, and Joy in your work and a pleasant time tending your gardens.
Corrections: An earlier version of this essay said that Pants was picked up by ex-Twitter engineers at other companies. In fact only one of the companies that became major users of Pants had an ex-Twitter employee. I also mistakenly identified the 2014 World Cup match between Germany and Brazil as the final, not the semi-final.